
1月19日,中共中央政治局常委、国务院总理李强主持召开专家、企业家和教科文卫体等领域代表座谈会,听取对政府工作报告、“十五五”规划纲要草案的意见建议。
MiniMax稀宇科技创始人、CEO闫俊杰出席座谈会并发言,成为继DeepSeek创始人梁文锋后,第二位参会的AI大模型企业代表。

闫俊杰,1989年生、河南人,MiniMax稀宇科技创始人和CEO。2015年7月获得中科院博士学位,在顶级会议和期刊上发表约200篇学术论文。
MiniMax成立于2022年,是全球领先的通用人工智能科技公司,自创立之初,就坚持文本、视频、语音全模态自研,是“全球唯四全模态进入第一梯队”的企业。今年1月9日,成立仅四年的MiniMax(股票代码:0100.HK)在港交所上市,刷新了AI公司的最快上市纪录。

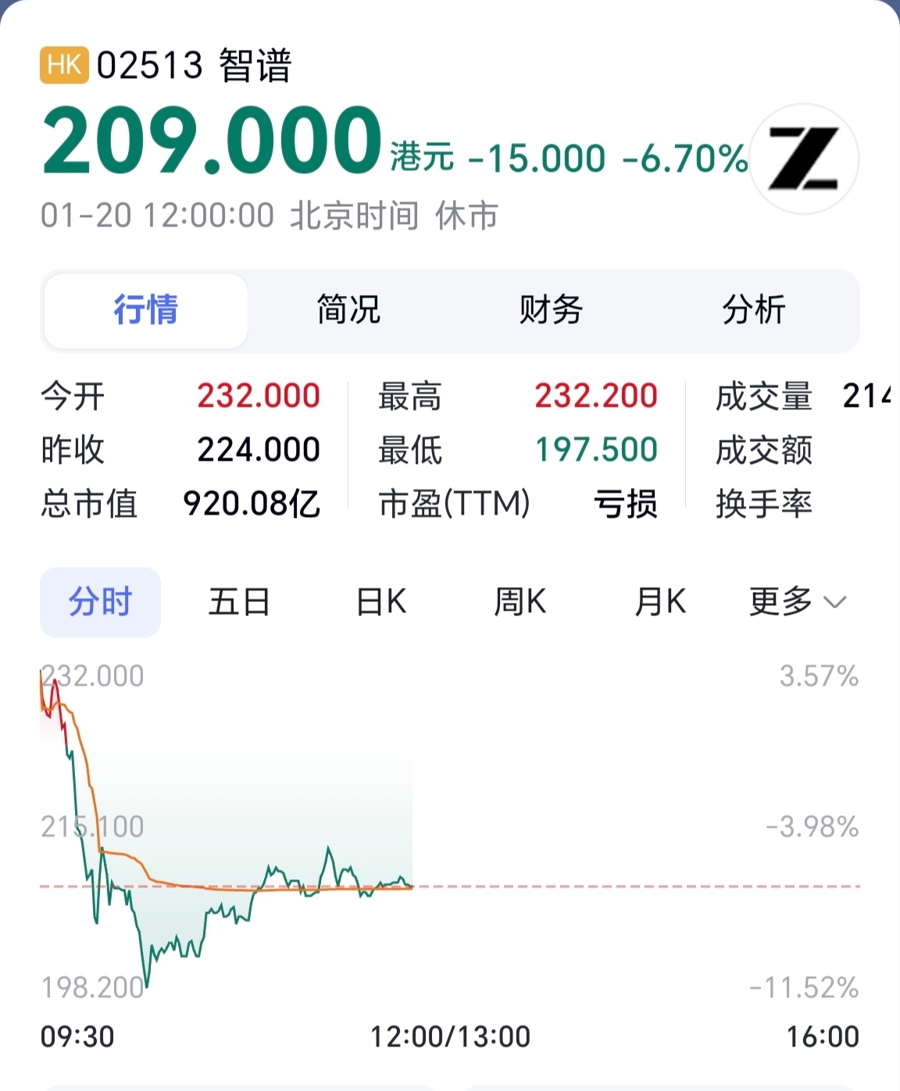
截至今天中午,MiniMax股价已达393.8港元,总市值破1235亿港元,市值已超过先于MiniMax在港交所上市的“大模型第一股”智谱AI(920亿元)。
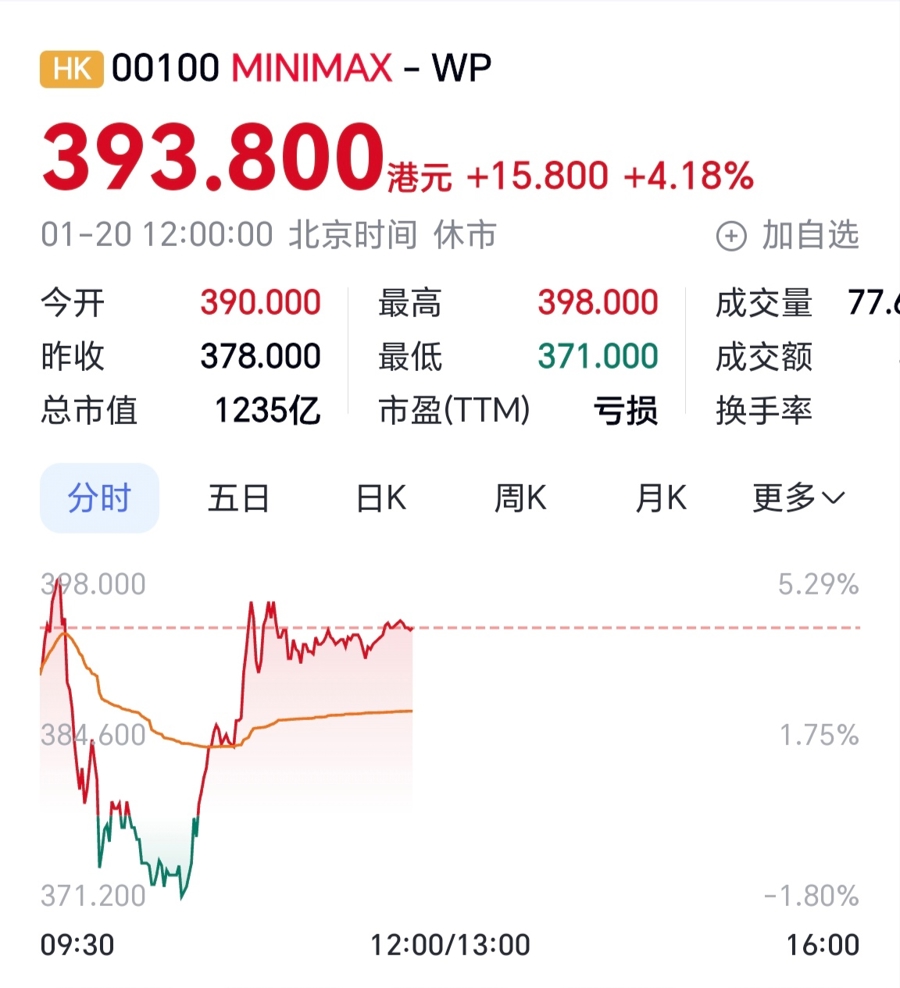
MiniMax迄今已有超过200个国家及地区的逾2.12亿名用户,以及来自超过100个国家及地区的企业客户,企业逾70%的收入来自海外市场。公司员工385人,平均年龄29岁,几乎“全员95后”,研发人员占比高达73.8%,人才密度极高。MiniMax约三分之一员工拥有海外教育工作背景。
从某种意义上说,MiniMax而今的主场时刻,是用“逆行”换来的。
2024年以来,迫于内部成本与外部竞争,国内外大模型公司多在加速收敛。到2024年7月,美国前六的AI创业公司只剩OpenAI和Anthropic。而国内,百模大战很快收缩为个位数竞争,曾经的大模型“六小虎”,不少转而押注行业落地。
MiniMax在迷雾中保持清醒果敢,是为数不多仍在坚持基座模型研发的创业公司。2023年下半年,国内同行多坚信大模型稠密架构,MiniMax却率先投入资源研究MoE架构。MoE架构将模型分成多个专家子网络,视情动态激活“专家”进行计算,以节省计算开销。2024年初,MiniMax上线国内首个基于MoE架构的大模型,而2025年初爆火的DeepSeek-R1使用的就是MoE架构。如今,MoE几乎取代稠密架构,成为行业主流。
MiniMax只用OpenAI不到1%的花销,就实现了全模态(语音、视频、文本)布局,除了最早采用MoE架构之外,另一核心秘笈在于使用了线性注意力机制。在模型传统的注意力机制中,token(模型输入、输出基本单位)长度与算力消耗呈平方关系,token增长百倍,算力消耗就增长万倍。线性注意力机制是在token长度增加后,努力让算力消耗呈线性增长。事实上,该理论2019年就有海外学者提出,但敢于投时间、人力、算力资源验证其可行性,并最终用于大规模商业化部署的,全球范围仅MiniMax一家。
大模型发展是一场长跑,其决赛季远未到来。面对平均每三个月就能带来“行业一震”,MiniMax保持敬畏,其目标始终就一个——留在牌桌上。
闫俊杰极少接受媒体采访,但在2024年世界人工智能大会上,他难得与记者多言几句。当时他谈及“生存”。他认为,技术上能快速进步、商业上能较好循环,唯有符合这两点的公司才能留下来。他还补充道:“在等待市场出现千万级乃至亿级AI应用过程中,大模型公司该做的,就是具备每年提升10倍的能力。我们成立迄今,正是按这个速度来的。”
(文章来源:上观新闻)





